FixBrowser
About FixBrowser
This page describes how FixBrowser works in a more detail and what makes it a good approach to web browsing compared to a regular web browser.
For description of FixProxy visit the blog post.
Parsing of HTML
At first the HTML is parsed according to the HTML5 specification. This specification is quite complex and confusing because it codifies existing ad-hoc parsing techniques that somewhat stabilized between the browsers over the time.
FixBrowser has about 30% coverage of tests which sounds very low, but in reality basically all websites are totally fine. I've seen just a few odd cases here and there from my experience from using FixProxy over multiple years. It's basically all about very weird edge cases. It is also very likely that relatively few changes can bring it very fast to much better coverage.
At this point the fix scripts are also applied to do any necessary adjustments due to not having JavaScript support. For some websites it means to load data from JSON and creating the corresponding HTML elements (eg. comments).
For most websites it's just a matter of small changes and there are also whole groups of websites using the same technology that it can be solved for many websites at once. Many websites don't need any changes at all.
Additionally some websites are harder to use, for example not all comments are loaded and you have to manually expand them. The fix scripts load all the comments and expand them for you. So once the page is loaded you have everything, improving the usability.
Parsing of CSS
Parsing of CSS is much better, the specification is very clear. The parsed CSS is applied to the HTML according to the selectors and the cascade nature of the stylesheets.
In a normal browser this step is what makes the internal structures quite complicated as you need to react to arbitrary dynamic changes. Remember that CSS is a very powerful language and a simple change can radically change the overall layout of the web page. And you need to implement it in a fast way so JavaScript heavy websites are not slow. This makes it even more complicated.
In comparison FixBrowser just need to apply the stylesheets using a straightforward recursive algorithm only once because it doesn't need to count with any dynamic changes after that.
Conversion to rich text
The HTML/CSS representation (DOM) is quite different from the view representation. In DOM you can make elements to float, put them to different layers and many other quite drastic changes. Therefore it needs to be translated to a view representation.
In a normal browser this needs to be always synchronized with the DOM because it can be updated at any time. A small change in DOM can make drastic changes in the view, and all these operations needs to be fast as well. Adding a LOT of complexity.
FixBrowser doesn't need to do any of it. You can start to see the pattern why FixBrowser is much much easier to implement. Similarly by not implementing JavaScript another big layer of complexity in itself is avoided.
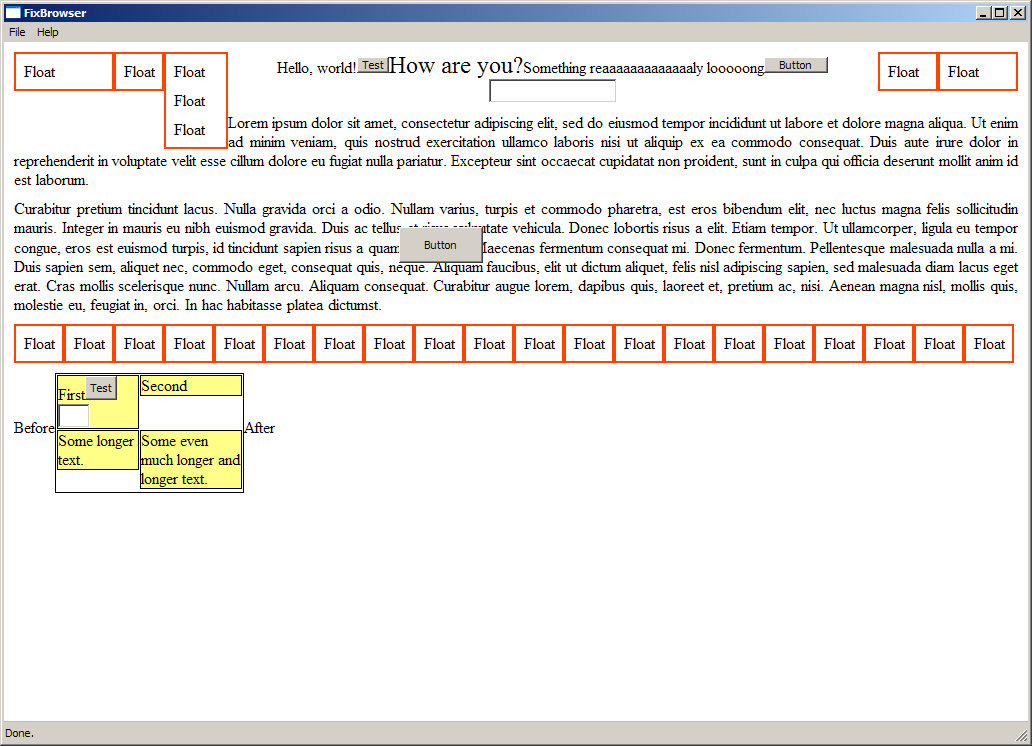
Rich text component
The rich text component has support for the hard parts of the layouting: text flow with floats. Anything else is less involved and it's basically just a block or an inline block in (nested/overlay) layers from implementation point of view. You can see yourself how it handles different widths with quite complicated test case:


Putting it all together
So after all the steps are done we can render the page in the rich text component. You can see the result below. The first image is rendered normally in Firefox (with adblock), the second is processed by FixProxy and rendered by Firefox.
Finally the third shows the result in FixBrowser. As you can see we're still not there but it's quite close. It just needs some more work on the translation from HTML/CSS to rich text.
")


A nice thing is that at this step all the information about HTML/CSS is not needed anymore and can be safely discarded. This means the RAM usage is quite reduced in comparison to a normal browser that needs to maintain not just the DOM but also all the related data structures used for making it fast.
The rich text representation is also made serializable so it can be easily stored to a disk for storing the sessions. It can be also compressed in memory to support showing of many tabs. Together with the disk storage it can support an extreme number of tabs with little of memory.
Ideal for use cases such as researching about multiple topics where you need it open for multiple weeks while you actively work with the information. Or simply when you use tabs instead of bookmarks because it's easier (hopefully some ways of making this less needed will be done in the future).
The website was designed for modern browsers and IE4+.